レプリケーションを構成したノードが障害が発生するなどにより停止して、再度オンラインに復帰したときのレプリケーションの復旧方法の例を記載します。実際には使用しているストレージのソリューションや障害の種類によって様々なオプションがあると思います。
前提として[MongoDB] ローカル環境にMongoDBを3つ起動してレプリケーションをセットアップするで作成した環境でレプリケーションを構成しているものとします。
1.自動的な普及とoplogのサイズ
普及手順の一例を記載しますといいましたが、実際は障害のは発生したインスタンスをオンラインに戻せば自動的にデータは同期されます。
これには条件があり、 オンラインに復帰した MongoDB の oplog コレクションに格納されている同期用のデータが古くなっていないことが条件となります。oplogコレクションは capped collection(キャップ付コレクション) という種類のコレクションで、事前に定められたサイズを超えるデータが投入されると古いデータから順番に削除されるようなコレクションです。
そのため、停止時間が長すぎると セカンダリとしてオンラインになった MongoDBの oplog のデータのオペレーションのログが 古すぎて PRIMARYのMongoDBインスタンスの oplog コレクションに存在しなくなっていると ログを転送できないので自動的に復旧できまなくなります。そのため oplog のサイズは非常に重要となります。
oplog のデータを確認するには MongoDBのインスタンスにクライアントシェルから接続して 次のようにコマンドを実行します。
use local
db.oplog.rs.find()
ちなみに、 system.replset コレクションには レプリカセットの設定が登録されています。下記のようにコマンドを実行すると 設定情報を確認できます。
test:PRIMARY> db.system.replset.findOne()
{ "_id" : "test", "version" : 3, "members" : [ { "_id" : 0, "host" : "SC7X03:40000" }, { "_id" : 1, "host" : "SC7X03:40001" }, { "_id" : 2, "host" : "SC7X03:40002", "arbiterOnly" : true } ] }
もしくは rs.conf()を実行してください。
db.getReplicationInfo() を oplog コレクションで保持することができるサイズ(MB)を確認できます。この値が 障害が発生してから普及するまで PRIMARYのoplog が新しいデータで 上書きされないように十分大きな値を設定します。48時間以内なら自動普及できるようにする場合は、実際に想定される ワークロードを実行して oplog コレクションがどの程度まで使用されるかを確認して サイジングを行ってください。
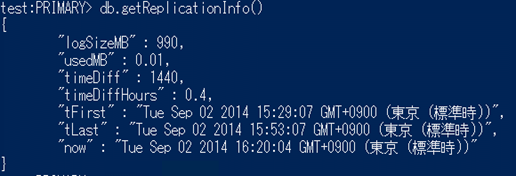
oplog のサイズは MongoDBのインスタンスを起動するタイミングで指定する必要があります。 --oplogSize オプションを使用します。
既定のサイズは 使用可能なディスク領域の 5 % を割り当てます。1G未満の場合は1GB割り当てます。まだ50GBを超えるサイズは割り当てません。
既定のサイズの詳細は http://docs.mongodb.org/manual/core/replica-set-oplog/ を参照してください。
2.完全に0から同期させる
oplogのデータが古くなった場合は、 復旧するノードのデータフォルダーのファイルをすべて削除し、中身を空にして 下記例のように MongoDB を再起動します。
.\mongod.exe --replSet test --dbpath=C:\Mongo\data\node2 --port 40001

自動的にデータの同期が開始されます。データが多いと同期の完了に時間がかかります。
3.新しいノード(インスタンス) を既存のノード(インスタンス) の代わりにレプリカセットのメンバーにする
レプリカセットに参加していたノードがハード障害により復旧が当分困難な場合、別のサーバー上にMongoDBをインストールしてレプリカセットのメンバーにすることができます。障害の発生したMongoDBに代わり新しくレプリカセットのメンバーに追加する MongoDBのインスタンスを起動します(下例参照 test はレプリカセット名)。
.\mongod.exe --replSet test --dbpath=C:\Mongo\data\node3 --port 40003
プライマリのMongoDBインスタンスに接続します。シェル上で次のコマンドを実行します。した例で test はレプリカセットの名前です。 localデータベースの db.sytem.replset を検索してレプリカセットの設定情報を取得します。
test:PRIMARY> use local
switched to db local
test:PRIMARY> config = db.system.replset.findOne()
障害の発生している 置き換え対象のレプリカセットのメンバーの設定(ホスト名) を 新しく起動した インスタンスの情報に置き換えます。下記が障害の発生したインスタンスの情報を 新しく 40003 ポートで起動したMongoDBに書き換えている例です。ここで SC7X03はホスト名です。rs.reconfig(config) で レプリケーションの設定を再設定しています。
test:PRIMARY> config.members[1].host = "SC7X03:40003"
SC7X03:40003
test:PRIMARY> rs.reconfig(config)
rs.status() を実行すると 新しく 40003 ポートで起動した MongoDB のインスタンスが SECONDARY になっていることを確認できます。
4.まとめ
簡単ですが説明は以上です。いろいろなケースをカバーできると思います。
何か指摘点などありましたらご連絡ください。