Sitecore とは直接関係ありませんが、Sitecore でも Solr を使用できるということで、Solr カテゴリーに Solr のユーザー辞書に単語を追加する方法の覚書を記載します。Web上にたくさんユーザー辞書に単語を追加する方法の覚書を記載しておきます。
検証環境
- Windows Server 2012
- Solr 4.6.0
Solr のセットアップ手順に関しては[Solr] Solr をセットアップするメモ を参照してください。
1. 既存のトークナイズの確認
下図のように Solrのサンプルサイトなどで text_ja 型のフィールドを解析してみます。 Analysis をクリックして インデックスを作成した文章を入力します。 FieldType には text_ja を選択します。こんかいは "サイトコアとSolrの連携テスト" と入力して Analyze Values ボタンをクリックしてみます。
そうすると、 サイトコアが サイト と コア と別々のトークンに分解されます。
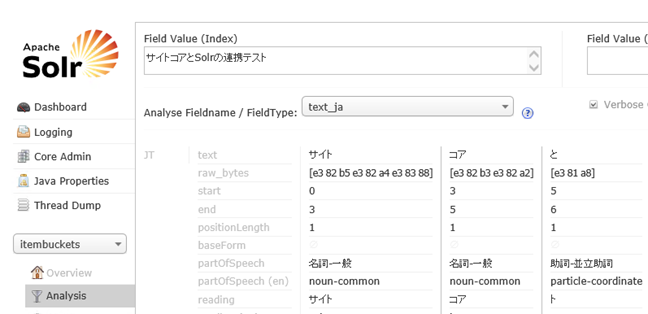
text_ja は サンプルの設定では JapaneseAnalyzer (kuromoji) という形態素解析を行うアナライザーを使用します。形態素解析の弱点として辞書に存在しない単語はうまく分割されない場合があります。Kuromojiは辞書内包型のトークナイザーなので、新しい辞書を組み込むには コンパイルをやり直す必要があるようです。その方法はSolrに詳しい有志の方が公開されている情報を参照してもらうとして、 JapaneseAnalyzer には ユーザー辞書を使用する機能があるので、今回はユーザー辞書を使用して新しい単語を登録する方法をご紹介します。
2.ユーザー辞書に単語を追加する
shcema.xml を表示して ユーザー辞書を使用するように設定します。text_ja のフィールド定義の tokenizer タグの userDictionary="lang/userdict_ja.txt" を追加します。ユーザー辞書の場所は Sol rのサンプルを流用している前提です。
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt" />
あとは userdict_ja.txt を編集します。このとき BOM(Byte order mark) なしの UTF-8 ファイルとして保存するようにします。メモ帳は使えません。
既存の userdict_ja.txt の書式に従って編集します。
# Custom entries サイトコア,サイトコア,サイトコア,カスタム人名
変更を保存して、Solr を再起動します。再度 Analysis 画面で サイトコアとSolrの連携テスト をtext_jaタイプで解析すると、次のように サイトコア が1つのトークンとして切り出されるようになります。
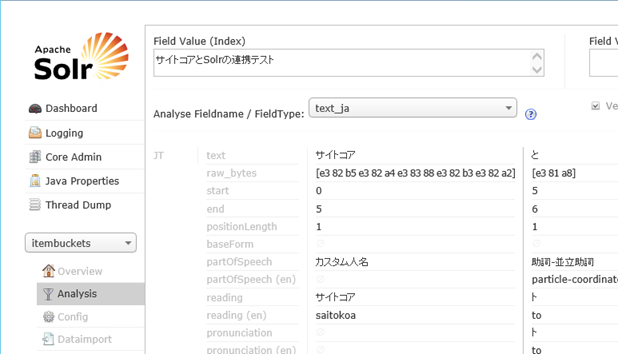
3.まとめ
説明は以上です。誤りや指摘点などがありましたらご連絡ください。